Unsupervised Transformation between Image Pixels and 3D Representations
In this project we aim to learn a mapping between 2D pixels and deformable 3D models in an unsupervised way. Approaches that learn on unlabeled data enable us to exploit almost unlimited amounts of data and thus have the potential to yield more robust models. Furthermore, an unsupervised approach can directly be applied to new object categories, avoiding repeating labeling efforts.
In a first attempt to simplify the problem we assume that a parametrized deformable 3D model is available. We do note that for many other object types (e.g cars, furniture, humans, animals) 3D models exist, or can be created from existing 3D data in an automated manner. In the following we consider human pose and shape estimation from unlabeled data as toy example.
We argue that a path through an intermediate representation facilitates the learning of a mapping from image pixels to 3D models. The choice of this intermediate representation is key and should fulfill the following constraints:
- support 3D inference
- be spatially related to the image pixels which makes the representation well-predictable by a CNN
- capture all relevant content of natural images
As illustrated in Figure 1, our intermediate representation of choice factors an image into a background, explicit part segments and a latent appearance code.
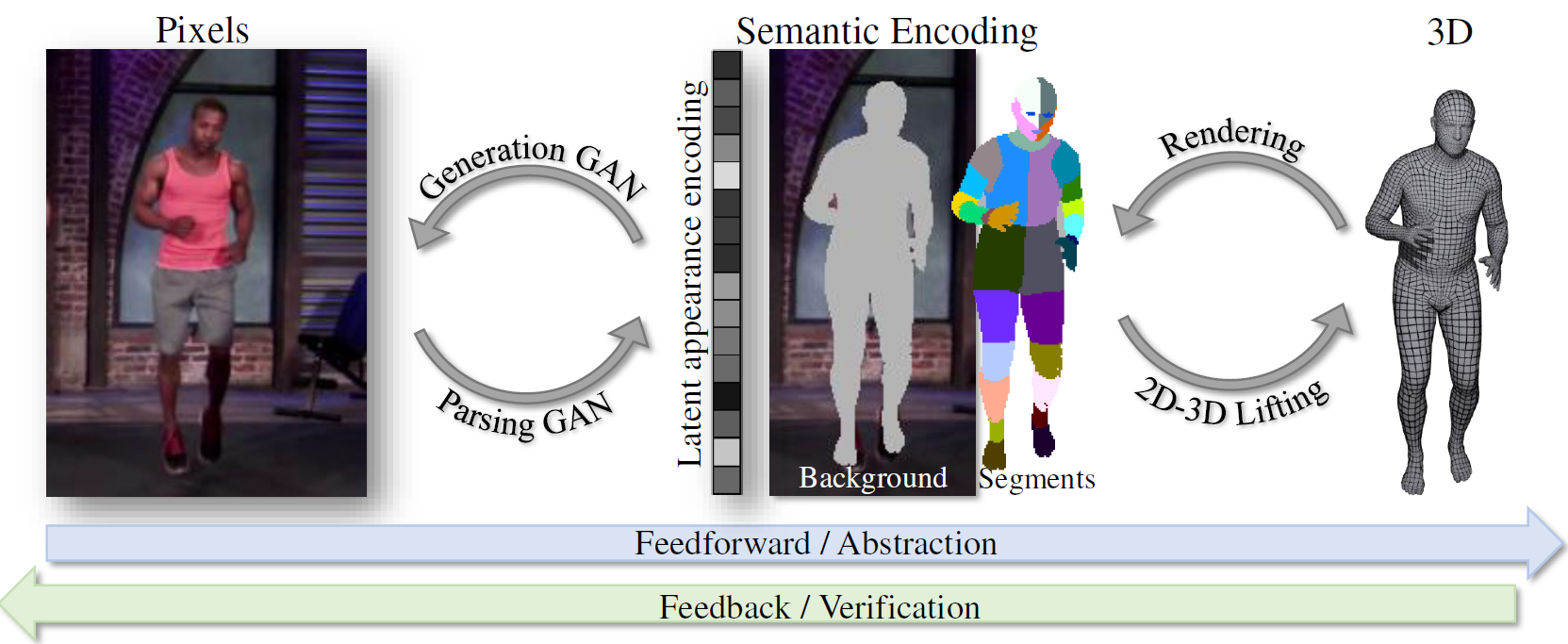
Exploiting ideas from CycleGAN we learn both directions of the cycle between image and intermediate representation in an unsupervised manner. Furthermore, we connect the intermediate representation to the parametrized 3D body model. Both cycles together can be used in a chain and it becomes feasible to translate between image and 3D model and vice versa.
One application of the chained cycles is human pose estimation as shown in Figure 2 for synthetic data and Figure 3 for in-the-wild images.


Our chain of cycle works in both directions and thus we are also able to transfer the appearance of a person to an other image (Figure 4, left) or to any other 3D model configuration (Figure 4, right).

Contact:
Nadine Rüegg,