Learning the Similarity for Classification
What if your dataset is small and/or doesn’t cover the full variability of the world ? Traditionally, in this case one has to:
- Regularize harder;
- Use simpler model;
- Perform data augmentation;
- Whatever;
to reduce overfitting.
The idea is to:
- leverage existing large scale image database for pertaining;
- Solve theoretically more difficult problem: learn similarity function in the space of arbitrary yet real images;
- Fine-tuning for the target dataset;
- Compute stochastic similarity measure with each class in test time.
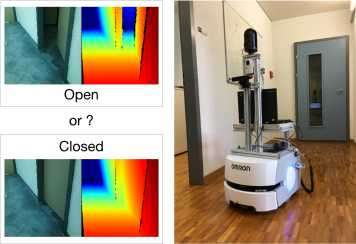
Typical usage example.
Publications:
Usvyatsov, M., Schindler, K.: external pageVisual recognition in the wild by sampling deep similarity functions. International Conference on Robotics and Automation, Montreal, Canada, 2019
Contact Details:
Mikhail Usvyatsov